

This is my essay distilling Kojima et al.’s May 2022 paper Large Language Models are Zero-Shot Reasoners. I had a lot of fun writing it, and I hope you enjoy reading it. Subscribing (free) will put any future read different think different essay into your inbox. Have a great day!

How smart are computers?
For most of the history of computing, the answer has been to correct a misunderstanding. Computers are not smart at all, they’re just fast. They show no reasoning ability and they struggle to do simple tasks presented to them without explicit instructions that are formatted correctly.
This is no longer the case.
With the advent of Large Language Models (LLMs), machine learning has turned the answer to this classic question on its head through creating programs that display basic reasoning out of the box.
In this essay, we will go over what LLMs are, what Kojima et al. discovered about their reasoning capabilities, and some consequences of their results.
To explain large language models, we will look at each term in the name in reverse order as I believe this is the best way to build intuition.
Models
Models are representations of objects or phenomena that allow us to reason about and predict aspects of said object or phenomena. Let’s develop an intuition for models through an example.
Say we’re selling books for $9 each to raise money for our local library. We want to be able to reason about the number of books we’d need to sell in order to pay for renovations to the 100th story atrium our library has. To do this, we can model the money made through our book sale as a linear equation.
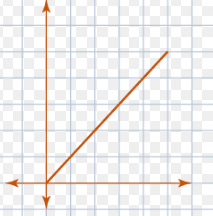
With this simple model, we can take the price of the renovations and figure out how many books we’d need to sell to successfully fund them. This model of book sales revenue may be imperfect (what if the sale inspires Michael Bloomberg to donate $100 million?), but it is definitely helpful.
In this simple situation, we made the model by hand and it allowed us to reason in every way we needed to about our situation (i.e. book sales revenue). Selling books for the same price isn’t a difficult phenomena to model, but what do we do if we want to model something more complex? When modeling weather, asset prices, or anything else in a dynamic and complex system, setting up your model by hand is extremely difficult. Often, you have a huge amount of data, but no solid understanding of your phenomenon. Enter machine learning.
Machine learning is one of the most hyped-up tools on the planet. Its form however is simple: making a computer use data to tune a model. Let’s use as an example the effect of global weather patterns on crude oil prices. If you try to model this by hand, you will spend an impossibly long time on it, your model will be terrible, or both. However, say you have 40GB of weather balloon data from around the world as well as similar amounts of pricing data, you could use machine learning to make a model far more nuanced than your hand tuned one.
Machine learning isn’t a general purpose savior, and at the end of the day the predictions you can make from your model are only as good as the fundamental assumptions your model makes about the structure of the phenomenon it attempts to represent. A machine learning technique like linear regression (using data to make a line) would hardly be more useful for something like oil pricing than making a graph by hand. When your assumptions line up with your phenomenon however, the results possible with machine learning are incredible.
Language
Pulling us back to our subject, we’re talking about Large Language Models. How can we model language?
The first step in modeling anything is distilling our subject to the most barebones representation of it that can still be useful. For language, we will go with this distillation: a language is a set of rules that tell us what words go after what other words. In a sense, putting one word after another is what made Shakespeare and John Steinbeck such legendary figures. With our fundamental assumption about the structure of language set, we can think about how we might go about building a more mathematical model of language.
A classic way to model a language is to take a huge amount of text (normally called a corpus), and for each word you find, look at the word after it. Keep track at what words you see after each word in our corpus of text. After doing this for the entirety of our dataset (which should comprise a large amount of different sources of text), we now have some word frequencies which will allow us to reason about what word will come next. This is called a Markov Chain model, and it was how Apple made its autocomplete software on the iPhone.

As anyone who has ever typed out a message only using the Apple keyboard’s suggestions knows, this model of our language really isn’t all that good. It kind of holds the essence of language, but not in any super useful way. You certainly couldn’t have a coherent conversation with this kind of language model.
How can we improve this performance? Here again enters machine learning.
In the 2017 paper Attention is All you need, Ashish Vaswani et al. released a machine learning model for language that would shape machine learning research for the next 5 years. The Transformer Architecture was released in this paper, and to this day (written November 2022) it is still the foundation of all state-of-the-art language models. The details of this model are very technical, and I won’t go in depth with them here (for those interested, the Illustrated Transformer series of blog posts is a phenomenal resource). What we want to look at here are the fundamental assumptions that underly this model. The transformer architecture assumes that
Words far back in the sequence/sentence/paragraph/document can be extremely relevant to what word comes next, and
Knowing which words to pay attention to is the key to correctly modeling languages.
As a short example, if I wanted a language model to continue this paper, I would hope that it pays attention to the headings Models and Language (which are fairly far back in the text) so that it could correctly predict that the next section would be titled Large.
After designing a model with these axioms in mind, the Google Brain team then fed 45 terabytes of text from the internet into this model so it could adjust itself until it knew what to pay attention to. This is the strength of machine learning in the modern age: people put obscene amounts of data on the internet for free. All of this text can allow the LLMs and other models to learn in the trial-and-error fashion that dominates this paradigm.
Large
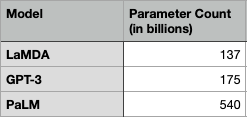
With our intuition for language modeling built, we can turn to what gives this subject its headline generating power: size. The best language models out right now (GPT-3, LamDa, PaLM are some good names to know) are huge. The scale of these models outpaces anything that’s been made before.
What do we mean by model size? How large are they? What does this imply?
To answer these questions, let’s return to the example from the modeling section: selling books. To represent this very simple situation, we used a linear equation.
 | Khan Academy")
We’re all comfortable with these as they’re normally one of the first topics covered in algebra. To be able to better understand the scale of LLMs, let’s use some new words in the context of our y = mx + b friend. The y value (in our case money raised from books) is a dependent variable that we are going to call the output. The x value is an independent value we’ll call the input. In machine learning parlance, this is a model with two parameters. Knowing that we’re using a linear model, we only need to know what m and b are equal to for defining our equation. With these two parameters, we can change how much money each book makes us, and how much money our library renovation fund initially starts with.
In the last section, we talked about the transformer architecture. How many parameters does the most successful transformer model have?
540 Billion.
Keep in mind, a linear model has two. This means that there are 540 Billion numbers inside this model meant to represent human language that can be tweaked, twisted, and tuned based on every bit of text on the internet.
A useful exercise for this is to visualize different spaces we could work in. With a one parameter model, we can think of a one dimensional space that our parameter moves in. In other words, a one parameter model can be thought of as a point on a number line.

Analogously, a two parameter model spans two dimensional space, and can theoretically cover any line we can make.

As you may have guessed, for a three parameter model we can utilizes 3 dimensional space (like we’re walking on hills!).
With four dimensions it gets dicier, but we could potentially represent points in a 3 dimensional space with a color for the fourth parameter. After this, all visualization bets are off. With each additional parameter, intuitively we understand that we can explore much more space thanks to the added dimension. When we scale this up to 540 Billion parameters, the space to explore is (to understate it) unfathomable.
What’s possible with a trained language model of this size? What abilities could be hiding in the folds of 540 Billion dimensional space?
LLMs in Action

Large language models generate conversant text that is indistinguishable from human text. There are some ways to trip these models up and fool them into showing their artificialness, but by and large they can speak as humans do. Already this technology is being put to use in industry, no only for customer service chatbots and call centers, but also for searching documents and finding relevant information online. In the most science-fiction-esque example, a google engineer famously claimed that their LaMDA model was conscious after using the chat program.
All of the above models are very good at modeling conversation. They are also all capable of writing blog posts and newspaper articles, and I have to suspect that a large number of publications are using this technology already (I promise austin is typing this, not GPT-3). For further examples, I highly recommend you check out these sources and stories. From fiction to war reporting, these bots are impressively good at writing. 15 years ago if you told someone a computer would have writing and speaking skills at this level, you’d have been laughed at. Now, it’s just where we are.
Going back to our discussion on model size, we can imagine that each time someone types a prompt or message to one of these LLMs a small part of that mind bogglingly large space is explored. In any space that large, assuming that people have explored everything the model has to offer in terms of ability is probably a bad bet. Kojima and his team at the University of Tokyo provide us with the perfect proof of this concept through their exploration of the reasoning ability of different LLMs.
Smarter than a fifth grader?
Computer scientists test the reasoning ability of language models the same way America tests the reasoning ability of its children: standardized test questions.

{kind=link}
{kind=link}
{kind=link}
A classic dataset to test and then score the reasoning ability of a model is the GSM8K, whose score is then used as a kind of metric to compare different LLMs to each other. If you were to see one of these questions on a common core styled exam, you wouldn’t even bat an eye. Scientists classify the reasoning ability of into two main categories: few-shot and zero-shot. This demarcation splits the examples of reasoning behavior into those where the computer is given some example questions and answers (few-shot), and those where the computer is given no examples and is tested on the question right away (zero-shot). For years it has been demonstrated and known in the AI community that large language models are good few-shot multi-task learners. This means that when shown a few examples of a task (think word problems or arithmetic), they can then learn it fairly well. What this knowledge led to was the crafting of massive fine-tuned datasets being made by hand to showcase and explore LLMs’ few-shot abilities. Another piece of knowledge that had been demonstrated plenty was that large language models are very poor zero-shot reasoners. Out of the box it appeared scores on test sets like GSM8K were pretty horrendous.
But remember: 540 Billion is HUGE! (And so is 175 Billion.)
Kojima et al. shook the machine learning world when they announced that all prior conceptions of AI zero-shot reasoning were wrong; the community simply hadn’t looked in the right place.
What does a great teacher do when teaching a child something? They tell the child to go step by step. What Kojima and his colleagues found out what that this is exactly what LLMs needed. Whenever a question (a.k.a. a prompt) was given, if the phrase “Let’s think step by step” was added to the prompt, then the zero-shot reasoning ability of the model skyrocketed. For example, on the previously mentioned GSM8K test, one model’s score shot from 10.4% to 40.7%. On another reasoning task, the score jumped from 17.7% to an astonishing 78.7%.

Sitting quietly on some innocuous hill in the 540 Billion dimensional space of our large language model was the ability to correctly reason with no help and no examples.
Conclusion
Large language models are computer programs that model human language ability. They use the principles of machine learning on an astounding scale to make programs with abilities that computers have never had before.
Kojima and his colleagues at the University of Tokyo and Google showed that hiding in these massive models is the ability to reason at an impressive level. All that was needed was an extra sentence added to the end of the question, which they called “Zero-shot Chain-of-Thought” prompting.
I will end this essay as Kojima et al. ended their paper: AI researchers (and people in general) should not simply accept what is common knowledge about the abilities of these models. The search for high-level abilities needs to continue.